情野 陸
研究背景・目的
人口減少・高齢化や運転者不足に直面する都市交通において, 需要の時間的・空間的偏在と供給制約の複合的な変化は, 固定的な路線・ダイヤを前提とする従来型システムの構造的限界を明確に示している. オンデマンド交通システムは利用者のリクエストに応じてリアルタイムに経路・配車スケジュールを決定する柔軟な交通サービスであり, 持続可能な移動基盤として期待されている. 国土交通省は 2023 年までに延べ 78 事業者の AI オンデマンド交通の導入を支援し, 2024 年の日本型ライドシェア解禁と相まってその社会実装は加速している.
しかしながら,既存研究の多くは単一時点での最適マッチングに焦点を当てており, 現在の配車決定が将来のサービス水準に与える影響を十分に考慮できていない. また,MaaS(Mobility as a Service)プラットフォームへの安定マッチング理論の適用(Liu・Chow, 2024)に代表される既存研究も, 主に静的な均衡状態の分析に留まっており, 自律的な意思決定を行う乗客・ビークル間の安定性を動的環境下で保証する理論的枠組みは確立されていない.
本研究では以下の 2 つの課題を解決する枠組みを構築する.
第一に,確率的な需要変動と車両位置の時間発展を考慮した上で,
長期的な社会的効用を最大化する最適マッチング方策をマルコフ決定過程 (MDP) として定式化し,動的計画法により導出する手法を提案する.
第二に,個々の参加者の期待効用を状態価値関数と整合的に定義し,
ブロッキングペア (BP) および拡張ブロッキングペア (EBP) による逸脱を防ぐ
インセンティブ設計問題を数理最適化問題として定式化することで,
静的な安定マッチング理論を動的な環境へと拡張する.
問題設定
サービス提供エリアは無向グラフ \(G = (\mathcal{N}, \mathcal{E})\) で表される (\(\mathcal{N} = \{1, \ldots, N\}\): ノード集合,\(\mathcal{E} \subseteq \mathcal{N} \times \mathcal{N}\): エッジ集合,各エッジは距離 1). システムの参加者として,乗客とビークルの二種類のプレイヤを考える.
乗客 \(\mathrm{ps}_{j,k}\) はノード \(j\) に滞在しノード \(k\) を目的地とする乗客を表す. ノード \(j\) への乗客出現確率を \(p_j\),目的地選択確率を \(p_{j,k}\) とし(\(\sum_{k \in \mathcal{N}} p_{j,k} = 1\)), これらは独立と仮定する. ビークル \(\mathrm{v}_i(n)\) はノード \(i\) に \(n\) ステップ後に空車状態で到着するビークルを表す(\(n=0\) は現在空車で待機中). サービス提供エリア内のビークル総数 \(M\) は常に一定に保たれる.
ある時点における全プレイヤの集合をプレイヤ集合 \(s\) と呼ぶ: \[ s \subseteq \{ \mathrm{v}_i(n) : i \in \mathcal{N},\, n \geq 0 \} \cup \{ \mathrm{ps}_{j,k} : j, k \in \mathcal{N} \} \] 全ての可能なプレイヤ集合の族 \(S\) を状態空間と定義する. マッチング \(M\) はペアの集合であり,全プレイヤがいずれか一つのペアに属するよう構成される: \[ \bigcup_{\mu \in M} \mu = s, \qquad \mu \cap \mu' = \emptyset \quad (\forall \mu \neq \mu' \in M) \] プラットフォーマは全ての方策の集合 \(\Pi\) の中から方策 \(\pi: S \to A\) を選定し, 各タイムステップでマッチング \(M_{\pi}(s)\) を決定する.
報酬関数とゼロ和制約
乗客 \(\mathrm{ps}_{j,k}\) の基礎的な報酬関数は: \[ R_{\mathrm{ps}_{j,k}}(s, M') = \begin{cases} r_j - \beta_j \cdot d(i,j) & \text{if マッチする場合}\\ -\beta_j & \text{if 取り残される場合}\\ \end{cases} \] ビークル \(\mathrm{v}_i(n)\) の基礎的な報酬関数は: \[ R_{\mathrm{v}_i(n)}(s, M') = \begin{cases} w \cdot d(j,k) - c \cdot (d(i,j) + d(j,k)) & \text{if マッチする場合}\\ -\alpha & \text{if 取り残される場合} \end{cases} \] プレイヤ \(\mathrm{p}\) の総報酬は,基礎的な報酬にインセンティブ \(u_{\mathrm{p}}(s)\) と金銭授受 \(v_{\mathrm{p}}(s)\) を加えた:
最適方策の導出(MDP の定式化)
本システムの時間発展プロセスはマルコフ性を満たすため, MDP \((S, A, P, R, \gamma)\) としてモデリングできる. プラットフォーマが方策 \(\pi\),プレイヤが方策 \(\pi'\) に従う場合の状態価値関数を以下のように定義する: \[ V^{\pi,\pi'}(s, u, v) := \mathbb{E}_{\pi'}\left[ \sum_{k=0}^{\infty} \gamma^k \hat{R}_{t+k} \,\middle|\, s_t = s \right] \] 上記のゼロ和制約より,状態価値関数はインセンティブ・金銭授受に依存せず, 実際に形成されるマッチング方策 \(\pi'\) のみによって定まることが定理として示される: \[ V^{\pi,\pi'}(s, u, v) = V^{\pi'}(s) = \mathbb{E}_{\pi'}\left[ \sum_{k=0}^{\infty} \gamma^k \sum_{\mathrm{p} \in s_{t+k}} R_{\mathrm{p}}\!\left(s_{t+k}, M_{\pi'}(s_{t+k})\right) \,\middle|\, s_t = s \right] \] この性質により,最適方策の導出とインセンティブ設計の二課題を独立に扱うことが理論的に正当化される.
状態価値関数はベルマン方程式を満たし, 最適状態価値関数 \(V^*(s)\) はベルマン最適方程式の一意な解として与えられる: \[ V^*(s) = \max_{M \in A_s} \left\{ \sum_{\mathrm{p} \in s} R_{\mathrm{p}}(s, M) + \gamma \sum_{s' \in S} P(s' \mid s, M)\, V^*(s') \right\} \] 最適方策は: \[ \pi^*(s) = \mathop{\rm arg~max}\limits_{M \in A_s} \left\{ \sum_{\mathrm{p} \in s} R_{\mathrm{p}}(s, M) + \gamma \sum_{s' \in S} P(s' \mid s, M)\, V^*(s') \right\} \] 状態空間・行動空間が有限の場合,価値反復法(Algorithm 1)によって \(V^*\) に収束することが理論的に保証される(縮小写像原理,\(\gamma < 1\)).
数値例(最適方策)
3 ノードのパスグラフ上に \(M = 1\) 台のビークルが存在し, ノード 2・ノード 3 に乗客が確率的に出現,全乗客の目的地はノード 1 とする設定で実験を行った(Table 1). ビークルの状態は \(\mathrm{v}_1(0)\) から \(\mathrm{v}_1(4)\) までの 5 通り,乗客の出現パターンは 4 通りとなり, システム全体の状態空間は全 20 通りである(Table 2). 複数のマッチング候補が存在する状態は \(s_2, s_3, s_4\) の 3 つのみであり, 考慮すべき方策は 12 通り(\(\pi_1, \ldots, \pi_{12}\))に限定される.
| パラメータ | 記号 | 値 |
|---|---|---|
| 運賃の単位距離あたりの係数 | \(w\) | 2000 |
| 単位距離あたりの運行コスト | \(c\) | 10 |
| ビークルの待機・実車中の不効用 | \(\alpha\) | 100 |
| 割引率 | \(\gamma\) | 0.95 |
| ノード 2 の乗客出現確率 | \(p_2\) | 0.8 |
| ノード 3 の乗客出現確率 | \(p_3\) | 0.2 |
| ノード 2 の乗客マッチング効用 | \(r_2\) | 1500 |
| ノード 3 の乗客マッチング効用 | \(r_3\) | 1250 |
| ノード 2 の乗客待機不効用 | \(\beta_2\) | 100 |
| ノード 3 の乗客待機不効用 | \(\beta_3\) | 50 |
Table 1: パラメータ設定
初期状態 \(s_1 = \{\mathrm{v}_1(0)\}\) から 200 タイムステップのシミュレーションを行い, 各方策の累積社会的効用 \(\sum_{k=0}^{t} \sum_{\mathrm{p} \in s_k} R_{\mathrm{p}}(s_k, M_{\pi}(s_k))\) を比較した. \(\gamma = 0.95\) で導出された最適方策 \(\pi_8\) は最終的に最も高い累積報酬を達成した. 方策 \(\pi_{12}\) はシミュレーション初期には高い報酬を示すが,長期的には \(\pi_8\) に及ばない. これは,目先の高い運賃収入を優先して拘束時間の長いマッチングを選択することが, 長期的にはシステム全体の機会損失につながることを示唆している.

Fig. 1: 各方策下での累積社会的効用の推移(π8 が最終的に最高値を達成)
安定化インセンティブ設計
動的な環境においては,エージェントは現時点の利得のみならず将来にわたる利得の期待値を含めた長期的視点で意思決定する. そこで,プレイヤ \(\mathrm{p}\) の期待効用を以下のように定義する: \[ V^{\pi,\pi'}_{\mathrm{p}}(s, u, v) := \mathbb{E}_{\pi'}\left[ \sum_{k=0}^{\infty} \gamma^k \hat{R}_{\mathrm{p}_{t+k}} \,\middle|\, \mathrm{p}_t = \mathrm{p},\, s_t = s \right] \] この期待効用は MDP の状態価値関数と同一の数学的構造を持ち,将来の状態遷移に伴う利得変動を考慮した合理的な意思決定を数学的に記述する.
期待効用はインセンティブ配分 \(u\) および金銭授受配分 \(v\) に関してアフィン関数となり, \[ V^{\pi,\pi'}_{\mathrm{p}}(s, u, v) = V^{\pi,\pi'}_{\mathrm{p}}(s, 0, 0) + \Psi^{\pi,\pi'}_{\mathrm{p}}(s, u) + \Phi^{\pi,\pi'}_{\mathrm{p}}(s, v) \] また,以下の再帰方程式を一意に満たす: \[ V^{\pi,\pi'}_{\mathrm{p}}(s, u, v) = \hat{R}_{\mathrm{p}}\!\left(s, M_\pi(s), M_{\pi'}(s), u_{\mathrm{p}}(s), v_{\mathrm{p}}(s)\right) \\ \qquad\qquad\quad + \gamma \sum_{s' \in S} P(s' \mid s, M_{\pi'}(s))\, V^{\pi,\pi'}_{\mathrm{p}'}(s', u, v) \]
動的 BP・EBP の定義と方策の安定性
プレイヤ集合 \(s\) においてのみ挙動を変更する逸脱方策集合を: \[ \Pi_\pi(\mu \mid s) := \left\{ \pi' \in \Pi \,\middle|\, M_{\pi'}(s) \in A(\mu\mid s),\quad M_{\pi'}(x) = M_\pi(x)\; (\forall x \neq s) \right\} \] と定義する.これを用いて,動的マッチングにおける BP を以下のように定義する: \(\mu \notin M_\pi(s),\; |\mu| \geq 2\) なるペア \(\mu\) が, \[ \exists \pi' \in \Pi_\pi(\mu\mid s) \;\text{s.t.}\; V^{\pi,\pi}_{\mathrm{p}}(s,u,0) < V^{\pi,\pi'}_{\mathrm{p}}(s,u,0) \quad (\forall \mathrm{p} \in \mu) \] を満たすとき,\(\mu\) は動的 BP である. 動的 EBP は,ペア内ゼロ和制約 \(\sum_{\mathrm{p} \in \mu} v_{\mathrm{p}}(s) = 0\) のもとで, 次を満たす逸脱方策 \(\pi'\) と金銭授受 \(v\) が存在する場合に成立する: \[ \exists \pi' \in \Pi_\pi(\mu\mid s),\; \exists v \;\text{s.t.}\; \begin{cases} \sum_{\mathrm{p} \in \mu} v_{\mathrm{p}}(s) = 0,\\[2pt] V^{\pi,\pi}_{\mathrm{p}}(s,u,0) < V^{\pi,\pi'}_{\mathrm{p}}(s,u,v) \quad (\forall \mathrm{p} \in \mu) \end{cases} \]
また,EBP の必要十分条件はペア全体の期待効用の総和比較に帰着される: \[ \exists \pi' \in \Pi_\pi(\mu\mid s) \;\text{s.t.}\; \sum_{\mathrm{p} \in \mu} V^{\pi,\pi}_{\mathrm{p}}(s,u,0) < \sum_{\mathrm{p} \in \mu} V^{\pi,\pi'}_{\mathrm{p}}(s,u,0) \] また,BP は EBP の金銭授受を伴わない特殊ケースであり, 方策の弱安定性(BP なし)・強安定性(EBP なし)に対して「強安定 \(\Rightarrow\) 弱安定」が定理として示される.
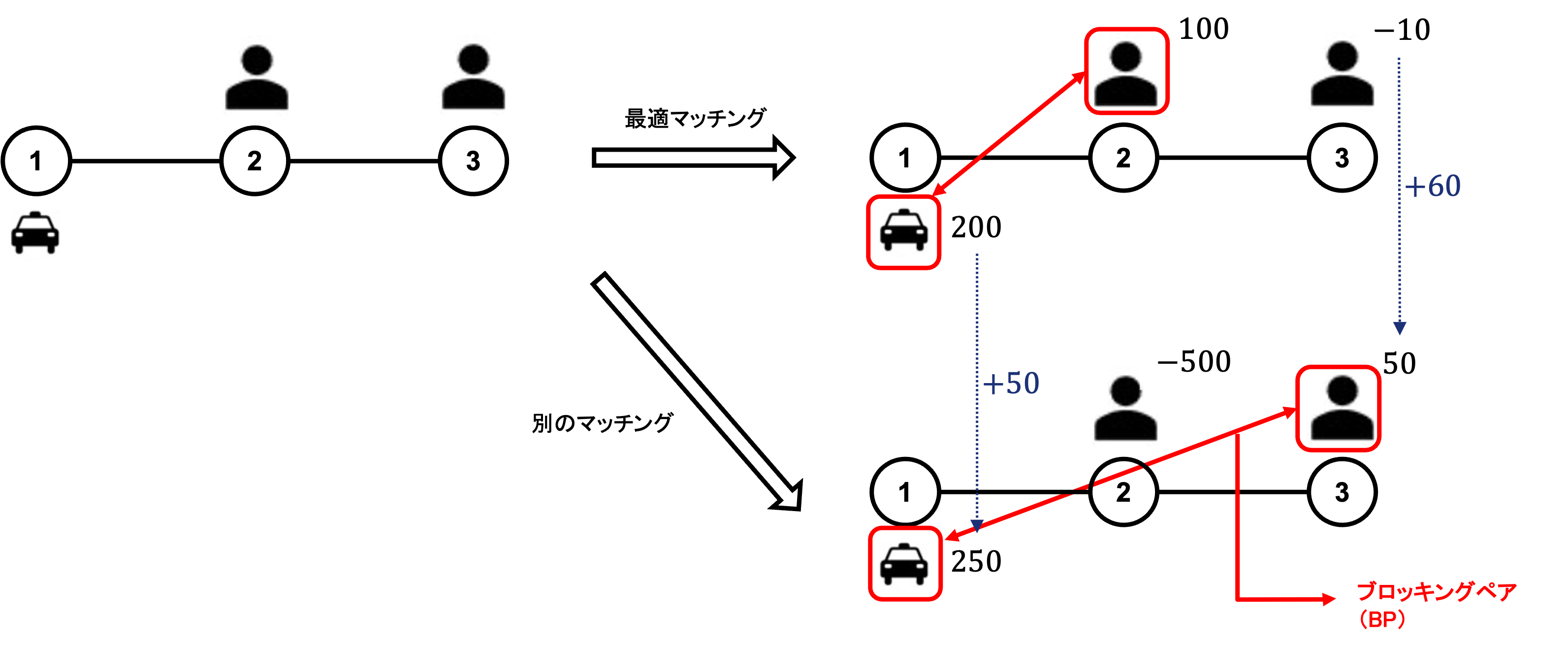
概念図:最適マッチングと別のマッチングにおけるブロッキングペア (BP)
インセンティブ設計の定式化
方策 \(\pi^*\) を所与とし,それを安定化するインセンティブ配分を以下の最適化問題として求める: \[ \begin{aligned} \min_{u'}\quad & \sum_{s \in S'} \sum_{\mathrm{p} \in s} |u_{\mathrm{p}}(s)|^2\\ \text{s.t.}\quad & \pi^* \text{ is stable (weakly or strongly)},\\ & \sum_{\mathrm{p} \in s} u_{\mathrm{p}}(s) = 0,\quad s \in S',\\ & u_{\mathrm{p}}(s) \geq 0,\quad s \in S',\; (\mathrm{p}) \in M_{\pi^*}(s) \end{aligned} \] ここで \(S' = \{s \in S : |A_s| \geq 2\}\) はマッチングの選択肢が複数存在する状態の集合である. 強安定性の条件は線形不等式制約として記述できるため,凸最適化問題となる. 弱安定性の条件は線形不等式制約の論理和として記述されるため,実行可能領域が非凸となる場合がある.
数値例(インセンティブ設計)
最適方策 \(\pi_8\)(\(\gamma = 0.95\))の安定化を対象とする. インセンティブ設計の対象は \(S' = \{s_2, s_3, s_4\}\) の 3 状態,決定変数は 7 次元ベクトル \(u'\) である. プレイヤ集合 \(s_4 = \{\mathrm{v}_1(0), \mathrm{ps}_{2,1}, \mathrm{ps}_{3,1}\}\) では, ビークル \(\mathrm{v}_1(0)\) と長距離客 \(\mathrm{ps}_{3,1}\) が結託し方策 \(\pi_{12}\) へ逸脱することで 双方の期待効用が増加する BP が生じる (インセンティブなし: ビークル \(19360.46 \to 19638.95\),長距離客 \(-419.05 \to 1150.00\)).
| プレイヤ集合 | プレイヤ | 弱安定化 \(u_{\mathrm{p}}(s)\) | 強安定化 \(u_{\mathrm{p}}(s)\) |
|---|---|---|---|
| \(s_2 = \{\mathrm{v}_1(0), \mathrm{ps}_{2,1}\}\) | \(\mathrm{v}_1(0)\) | -19.58 | -88.17 |
| \(\mathrm{ps}_{2,1}\) | 19.58 | 88.17 | |
| \(s_3 = \{\mathrm{v}_1(0), \mathrm{ps}_{3,1}\}\) | z\(\mathrm{v}_1(0)\) | 2.17 | 0.96 |
| \(\mathrm{ps}_{3,1}\) | -2.17 | -0.96 | |
| \(s_4 = \{\mathrm{v}_1(0), \mathrm{ps}_{2,1}, \mathrm{ps}_{3,1}\}\) | \(\mathrm{v}_1(0)\) | 40.40 | 101.33 |
| \(\mathrm{ps}_{2,1}\) | -40.40 | -262.51 | |
| \(\mathrm{ps}_{3,1}\) | 0.00 | 161.18 |
Table 3: 各プレイヤ集合/プレイヤにおける安定化インセンティブの計算結果
算出されたインセンティブ配分が実際の安定性に与える影響を, プレイヤ集合 \(s_4\) における各プレイヤの期待効用で検証する(Table 4). 比較対象の逸脱時の値は,ビークル \(\mathrm{v}_1(0)\) と長距離客 \(\mathrm{ps}_{3,1}\) が結託して方策 \(\pi_{12}\) を選択する場合のものである.
| プレイヤ | 方策 | (1) インセンティブなし | (2) 弱安定化 | (3) 強安定化 |
|---|---|---|---|---|
| \(\mathrm{v}_1(0)\) | 最適 \(\pi_8\) | 19360.46 | 19733.29 | 20283.64 |
| 逸脱 \(\pi_{12}\) | 19638.95 | 19733.29 | 19759.59 | |
| \(\mathrm{ps}_{2,1}\) | 最適 \(\pi_8\) | 1400.00 | 1359.60 | 1137.49 |
| 逸脱 \(\pi_{12}\) | 185.09 | 119.85 | -263.93 | |
| \(\mathrm{ps}_{3,1}\) | 最適 \(\pi_8\) | -419.05 | -419.64 | 787.13 |
| 逸脱 \(\pi_{12}\) | 1150.00 | 1150.00 | 1311.18 | |
| ペア合計 \((\mathrm{v}_1(0) + \mathrm{ps}_{3,1})\) | 最適 \(\pi_8\) | 18941.41 | 19313.65 | 21070.77 |
| 逸脱 \(\pi_{12}\) | 20788.95 | 20883.29 | 21070.77 |
Table 4: プレイヤ集合 \(s_4\) におけるインセンティブ適用前後の期待効用比較
列 (1) に示すように,インセンティブなしの場合,最適方策 \(\pi_8\) に従うビークルの期待効用(19360.46)は 逸脱時(19638.95)を下回り,長距離客 \(\mathrm{ps}_{3,1}\) の期待効用も \(-419.05\) から \(1150.00\) へ増加するため, 双方にとって逸脱が有益となり BP が形成される. 列 (2) の弱安定化インセンティブを付与した場合, 最適方策におけるビークルの期待効用が 19733.29 まで引き上げられ逸脱時と等しくなる. BP が成立するためにはペア内の全員が逸脱によって厳密に利益を得る必要があるが, ビークルにとっては逸脱による期待効用の厳密な増加が得られないため,BP の形成が阻止される. 列 (3) の強安定化インセンティブを付与した場合, 最適方策における \(\mathrm{v}_1(0)\) と \(\mathrm{ps}_{3,1}\) の期待効用の合計(21070.77)が 逸脱方策 \(\pi_{12}\) における合計と完全に一致する. EBP の成立条件はペア全体の総効用が逸脱によって厳密に増加することであるが, 本結果では総和が増加しないため,いかなる金銭授受を行っても双方の利益を同時に高めることは不可能となり, EBP も阻止される.
また,インセンティブの実行可能領域を可視化した結果(Fig. 2), 強安定性を保証するインセンティブ領域は凸集合(強安定性条件が線形不等式制約の論理積で記述されるため), 弱安定性を保証する領域は非凸な形状(弱安定性条件が論理和で記述されるため)となること, および強安定性領域が弱安定性領域の内部に包含されることが数値的検証として確認された.

Fig. 2 (a): 弱安定化インセンティブの最適解の配置

Fig. 2 (b): 強安定化インセンティブの最適解の配置
方策の安定化可能性
以下,報酬関数に含まれるパラメータを \(\theta = (w, c, \alpha, r_1, \cdots, r_\mathcal{N}, \beta_1, \cdots, \beta_\mathcal{N})\) とする. 前節の数値実験では特定のパラメータ設定下でインセンティブ配分が存在することを確認したに過ぎない. 一般に,道路網のネットワーク構造・需要の発生確率・報酬パラメータ \(\theta\) が異なれば, 最適方策を安定化させるインセンティブ配分が存在するとは限らない. 本節では,与えられた方策がそもそもインセンティブによって安定化可能かを判定する解析的枠組みを提案する. 弱安定性・強安定性それぞれに対応して,弱安定化可能性・強安定化可能性を定義し, 「強安定化可能 \(\Rightarrow\) 弱安定化可能」が示される.
線形不等式系への帰着
収支制約に基づいてインセンティブ変数の次元削減を行うことで, 弱安定性・強安定性の条件はいずれも,あるベクトル \(z\) に関する 線形行列不等式(線形不等式系)として記述できる. 特に,弱安定化可能性は複数の線形不等式系の解の存在条件の組み合わせとして, 強安定化可能性は単一の線形不等式系の解の存在条件として表される. 本研究ではこの表現を用いて,各方策の安定化可能性を数値的に評価する.
Farkas の補題による代数的条件
弱・強安定化可能性の条件は最終的に線形不等式系 \(Hz \leq h\) の解の存在判定に帰着される. Farkas の補題によれば,この系が解を持たないための必要十分条件は \[ \exists\, y \geq 0 \;\text{s.t.}\; H^\top y = 0,\quad h^\top y < 0 \] であり,したがって解を持つ(安定化可能である)ための必要十分条件は, \(H^\top y = 0,\, y \geq 0\) を満たすすべての \(y\) に対して \(h^\top y \geq 0\) が成り立つことである. 検証すべきベクトルの集合 \(\mathcal{C} = \{ y \mid H^\top y = 0,\, y \geq 0 \}\) は凸多面錐であり, Minkowski–Weyl の定理より有限個の極線 \(y^{(1)}, \ldots, y^{(n)}\) が存在して任意の \(y \in \mathcal{C}\) は 非負結合 \(y = \sum_k \alpha_k y^{(k)}\) で表される. したがって,安定化可能性の判定には極線 \(y^{(k)}\) についてのみ \[ h^\top y^{(k)} \geq 0 \quad (k = 1, \ldots, n) \] を確認すれば十分であり,本研究ではこの有限個の代数的不等式を用いて 報酬パラメータ \(\theta\) に関する安定化可能領域を特徴づける.
数値例(安定化可能性)
\(\pi_5\)–\(\pi_{12}\) の 8 通りの方策について,弱・強安定化可能条件を導出した(多面体計算ライブラリ MPT3 を使用,\(\pi_1\)–\(\pi_4\) は \(s_4\) で全員がマッチされないため実用上除外). 弱安定化可能性については,\(\pi_7, \pi_8, \pi_{10}, \pi_{12}\) は \(\theta\) に依存せず常に弱安定化可能であり,\(\pi_5, \pi_6, \pi_9, \pi_{11}\) は条件付きで弱安定化可能(条件は複数の線形不等式系の組み合わせで表現される). 強安定化可能性については,\(\pi_8, \pi_{12}\) は常に強安定化可能であり,残りの方策は \(\theta\) に関する連立線形不等式が条件として導出される. 強安定化可能 \(\Rightarrow\) 弱安定化可能の帰結は数値的にも確認され,\(\pi_7, \pi_{10}\) のように弱安定化可能であっても強安定化には追加制約を要する例が得られた.
条件付き安定化可能な方策では,安定化条件に \(w \leq 2c\) が含まれる場合が多い一方,ビークルの利潤確保条件は \(w \gt 2c\) であるため,安定化領域と利潤確保領域の共通部分が存在せず実システムへの適用が困難となる. これに対し,\(\pi_8, \pi_{12}\) は任意の \(w \gt 2c\) において安定性を保持できるため,工学的な応用可能性の観点から優位性が支持される.
まとめ
本研究では,オンデマンド交通システムにおける乗客・ビークルのマッチング問題について, 以下の 3 点の成果を得た. 第一に,MDP に基づく最適方策の導出手法の提案と,近視眼的方策の長期的な機会損失を数値的に実証したこと. 第二に,期待効用に基づく動的 BP・EBP の定義と, インセンティブ設計問題を凸最適化として定式化し方策の安定性を保証できることを数値的に実証したこと. 第三に,Farkas の補題を用いて安定化可能性を \(\theta\) に関する代数的条件として記述する枠組みを確立し, 報酬パラメータの値に依存せず常に安定化可能な構造的に堅牢な方策(\(\pi_8, \pi_{12}\))の存在を示したこと.
今後の課題
今後の展望として 3 点が挙げられる. 第一に,通勤ラッシュ等の時間依存需要を考慮した非定常 MDP への拡張や, 複数乗客の同時待機・ライドシェアリングを許容するモデルへの拡張である(状態空間の組合せ爆発には関数近似を用いた強化学習が必要). 第二に,功利主義的な目的関数に代わり,交通弱者や過疎地域の住民への 一定水準以上のサービス提供を保証する包摂性を考慮した重み付き目的関数の導入である. 第三に,旅客輸送と貨物輸送を統合した貨客混載システムへの本枠組みの拡張であり, 積載容量制約・配送時間枠の遵守を考慮した統合的な枠組みの構築が求められる.
参考文献
[1] 国土交通省. 社会資本の維持更新に関する研究. 2023.
[2] Gregory Trencher et al. Smart mobility innovations in regional transport services. Frontiers in Sustainable Cities, 2025.
[3] Jean-François Cordeau and Gilbert Laporte. The dial-a-ride problem: models and algorithms. 2007.
[4] 山本英里 et al. ライドシェア乗客間マッチングを取り入れた貨客混載システムの分散型経路最適化. 自動制御連合講演会, 2022.
[5] D. Gale and L. S. Shapley. College admissions and the stability of marriage. The American Mathematical Monthly, 69(1):9–15, 1962.
[6] Bingqing Liu, Joseph Y. J. Chow. On-demand mobility-as-a-service platform assignment games with guaranteed stable outcomes. Transportation Research Part B, 188:103060, 2024.
[7] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction. MIT Press, 2018.
[8] Richard Bellman. A Markovian decision process. Journal of Mathematics and Mechanics, 6(5):679–684, 1957.
[9] 竹内和雅. マッチング理論に基づくシェアリングシステム設計. 2020年度修士論文, 2020.
[10] Achim Bachem and Walter Kern. Linear Programming Duality. Springer, 1992.
[11] Alexander Schrijver. Theory of Linear and Integer Programming. Wiley, 1986.
[12] M. Herceg et al. Multi-Parametric Toolbox 3.0. Proc. European Control Conference, pp. 502–510, 2013.
2026年 1月20日