研究背景・先行研究
非協力ゲーム理論とその応用
近年, 非協力ゲームを用いたマルチエージェントシステムの応用が盛んである. 非協力ゲームでは, プレイヤーが, 他のプレイヤーと協力することなく, 自分の効用関数が大きくなる状態を目指して振る舞う. この非協力ゲームの分野の応用として, 様々な分野での活用が期待されている. 特に, 交通制御の分野や電力関連の分野で非協力ゲームの実用に関する研究が盛んである.まず交通制御の分野では, [1]では道路料金による交通制御が研究されている. また, [2]では, 駐車場に関する情報を踏まえた交通モデルとその分析を行っている. 自動車を利用した休日の買い物による交通への影響は, 行き先の駐車場の特性に大きく左右される. 現代においては駐車場の待ち時間などの情報が出発前に分かるため, これにより行動に変化が生じる.この行動をマルチエージェントシステムを用いて分析している.
電力関係の分野では, [3]において電力の安定した供給を行うための価格設定が研究されている. また, [4]ではEVの充電/放電の最適化を目的としている。充電/放電を非協力ゲームのモデルにしている。効用関数として、放電による収入の最大化に加え、ピーク時の電気料金を避け充電にかかる費用を減少させるものになっている. さらに, [5]では, 電力システムの効率化のためのデマンドレスポンスについて扱っている. デマンドレスポンスにおけるダイナミックプライシングの手法を分析している. 交通制御分野・電力分野以外でも非協力ゲームの応用は盛んである. [6]ではプレイヤー間での資源の配分への応用が研究されている. [7]ではゲーム理論を用いてコンテンツを視聴するかどうかを分析している. [8]では, デジタル指紋を回避してデジタルデータの違法コピーを行う集団の振る舞いを非協力ゲームのモデルを利用して再現している. また, 市場に関する応用も存在する. [9]では, 需要関数が不合理である寡占ゲームにおけるナッシュ均衡の安定性とbounded delayed rationalityの関係について扱っている. 需要関数が不合理である寡占ゲームはカオス的な振る舞いをするが, bounded delayed rationality の戦略の重み係数の値によってナッシュ均衡が安定である範囲が変化することを発見している. [10]では風力発電施設に対するアンケート結果を, 支払意思関数モデルのパラメータを求めることで分析し, 自然環境の価値を経済学的に評価しようとしている. このように, 非協力ゲームの実用に関する研究は多く行われている.
効用関数の未知性
非協力ゲームの応用時に課題になる点として, 効用関数の情報が未知であるという点がある. 非協力ゲームにおける効用関数は個人情報であり, 効用関数のパラメータは他のプレイヤーやシステム設計者から見て基本的には未知である. そのため, 未知の部分が存在する効用関数を扱う研究が行われている. 効用関数が未知となる例としては[11], [12]が存在する. [11]では, 通信への情報の埋め込みと解読をゲーム理論を用いて解析を行なっており, プレイヤーの効用関数の特定が困難であるとされている. [12]では, AttackerとDefenderの2プレイヤーでのsecurity gameで, decision error とobservation errorgが存在する場合を考えている. 相手の情報に誤りがのるという, 効用関数の一部が未知である状況に近い状態での振る舞いを観察している. このような未知の効用関数への対応を扱う研究も行われている. [13]では非線型のCournot duopoly gameを, best response dynamicsによってシステムとしている. このシステムはカオスを含む複雑なものである. この研究ではadaptive adjustmentを用いて短い区間での振る舞いを予測している. 扱う対象が未知のシステムには, 対象に不確かさが含まれるものも存在する. [14]では, 不確定さを含むone-shot gameにおける, 望ましい状態を設計する手法について扱っている. また, 不確かさを扱う方法としてロバスト制御が存在する. [15]では, 不確かさを含んだ関数に対して条件をつけることにより, ロバスト制御を行っている. さらに, リッカチ方程式を用い, パラメータが未知であっても制御を可能にしている. [16]では, multiparameter singularly perturbed system(MSPS), 特に inifinite horizon MSPSにおけるナッシュ均衡を実現する戦略の設計を行なっている. 効用関数の戦略に関する項に不確かさの含まれるパラメーターが存在する場合に, 高次近似を用いて戦略を設計している. [17]ではロバストなゲームを用いて複数の電気自動車の充電計画の最適化を目指している. 各電気自動車は料金を最小化することを目的とし, 電力の供給側は余剰の電力を電気自動車に販売する電力による収入を最大化することを目的にしている. これをStackelberg Game Modelを用いて最適な充電計画を求めるアルゴリズムを提案している. 電力の需要を不明と考え推定値を用い, 推定値から一定値以内に真の値があるとし, ロバストなゲームを考えている. また, 未知の効用関数に関わる問題として, Robust strategiesの達成を目指すものが存在する. [18]においては, 不確かさの影響を受けるMulti-Model liner quadratic (LQ) differencial gameでのRobust strategiesの達成を扱っている. Integral Sliding Model(ISM)という手法により, 入力を加えることで不確かさを消去した等価なダイナミクスとして扱うことでこれを達成している. また, [19]においてNエージェントのliner quadratic differencial game(LQDG)におけるfeedack strategyの設計を行なっている. 各エージェントはゲームのモデルは知らず, 各自がゲームのモデルのアイデアを独自に持っているという設定である. N個のリッカチ方程式を解くことで設計を行っている. このため, 選択だけが全体のモデルと各エージェントが想像したモデルで一致するため, 不確かな部分が存在する条件となる.ナッシュ均衡
効用関数の未知のパラメータが問題となる原因の一つにナッシュ均衡の存在がある. 非協力ゲームではナッシュ均衡と呼ばれる状態にになることが望ましい. 安定なナッシュ均衡の場合は非協力ゲームは最終的にナッシュ均衡に収束する.しかし, ナッシュ均衡には不安定なものも存在する. ナッシュ均衡が不安定な場合, プレイヤーはナッシュ均衡へ収束しない振る舞いをする. そこで非協力ゲームをシステムとして扱い, 不安定ナッシュ均衡を安定化させるための研究が行われてきた.ナッシュ均衡の探索
まず, ナッシュ均衡を安定化させるためには, ナッシュ均衡を知る必要がある. ナッシュ均衡は効用関数のパラメータから算出することができる. しかし, 効用関数のパラメータが未知の場合, ナッシュ均衡を導出することが困難である. そのため, パラメータに未知の要素がある状態でナッシュ均衡を求める研究が行われている. [20]では, 他のプレイヤーのモデルに関する情報を得ずにナッシュ均衡の発見を実現している. しかし, この手法では前にナッシュ均衡の情報を得ることができない.ナッシュ均衡の安定化
そこで, ナッシュ均衡の値を求めずにナッシュ均衡の安定化の実現を目指す研究が行われている. [21]において, プレイヤーにとって他の効用関数が未知の場合に, 効用の値のみから適切な方法を用いて次の行動を決定することによって, ナッシュ均衡の安定化を行なっている. さらに, [21]においてはモデルを用いずにナッシュ均衡を安定化する行動を設計している. [21]では各エージェントは自分の効用関数に関する情報を知らないまま,その場合での効用関数の値のみから次の行動を決める状況を扱う. ナッシュ均衡を安定化するような行動を設計することにより, 安定化を達成している. [22]では, ロバスト制御を活用し, 未知のダイナミクスで外乱の存在するネットワークゲームでのナッシュ均衡の探索と安定化を行なっている. [22]では, 状態の値と入力を除いたダイナミクスの値の推定値の差を用いてロバスト制御を行い, ナッシュ均衡を安定化させる入力を設計している.ナッシュ均衡が未知の場合
ナッシュ均衡が未知な場合は, 別の平衡点を用いる場合がある. [23]では, Soft-Constrained Nash Equilibria, Hard-Bounded Nash Equilibriaの存在に関する考察を, H∞制御の手法を用いて行う. [24]では, 各エージェントにとって他のエージェントに関する情報が未知である場合のシステムについて考察している. [24]ではBayesian gameを扱うため, ナッシュ均衡ではなくBayesian Nash equilibriaを使う. また, [18]では不確かな定数項が加えられたmulti-model LQ differential gameに対してOpen Loop Robust Nash Equilibriumを考え, その平衡点への収束の条件について考察を行なっている. [25]では, 制約を持った動的ゲームにおいて, コントロール変数が状態と連動して変化する場合を扱っている. このようなconstrained linear-quadratic difference gamesにおけるconstrained feedback nash equilibriumの探索を行っている. constrained feedback nash equilibrium は parametric feedback Nash equilibrium から得られるとされている. さらに、2つのマルチパラメータマップの交点の解析を行ない, その意味について言及している.また, ナッシュ均衡の推定値を利用する場合として[26]が存在する. しかし, 実際の振る舞いの前にナッシュ均衡を特定することは困難である.パレート改善
非協力ゲームにおいて, ナッシュ均衡は必ずしも最も良い状態ではない. パレート改善と呼ばれる, どのプレイヤーの効用も下げることなく, 全体の効用の和を上げることができる状態の移動が存在する. パレート改善をシステムに組み込む手法には[27], [28]が存在する. [27]では, パレート改善基準を用いて小規模水力発電の料金に税・補助金を加え価格設定を行っている. [28]では, 交通のボトルネックによって発生する渋滞を, ボトルネックの通行権によって抑えるという目的のもと, 提案手法によりパレート改善が実行されたか否かを確認している. パレート改善が実現される点を見つけることができれば, 目標値として望ましい. パレート改善を実現する点を見つける手法として, [29]では進化的アルゴリズムの応用を用いたパレート最適な解の探索が行われている. パレート改善が実現する点についても, プレイヤーの効用関数が未知の場合は発見が困難である. したがって, 効用関数のパラメータを知る必要がある.効用関数のパラメータの推定
効用関数のパラメータについては, [30]のようにある区間の振る舞いから他の区間での振る舞いを推定する手法や, [31]のように過去の情報からパラメータの値を推定する手法, [32]のように実行時の履歴から推測し利用する手法が存在する.しかし, これらの手法では, 振る舞いの開始時点では効用関数の情報を用いることができない.申告システムと耐戦略性
振る舞いの開始時から情報を利用したい場合は, プレイヤーに効用関数を申告してもらう必要がある. プレイヤーに情報を申告してもらう際に, プレイヤーが自分の効用を上げるために不正確な情報を申告する場合がある. これを戦略的な申告と呼ぶ. 戦略的な申告を防ぐ仕組みとして耐戦略性を備えたシステムが存在する. 耐戦略性を備えたメカニズムの研究は多数存在する. [33]では, 非協力ゲームを用いた電波帯域の動的な分配の際に, 自分の効用を上げるために虚偽の情報を送るプレイヤーがいる場合を扱う. [34]では, 一般的なonline optimizationにおけるアルゴリズムを, 正直な申告を行うようなアルゴリズムにする手法について扱っている. このような, 耐戦略性を踏まえたシステムの設計は, メカニズムデザイン(制度設計)と呼ばれる. [35]では, メカニズムデザインはエージェント同士が安全に取引できるようなルールの設計を目指したものであり, ゲーム理論/ミクロ経済学の一分野として研究が行われてきたと述べている.耐戦略性とオークション
メカニズムデザインの対象として特に研究が盛んな分野に, オークションが存在する. [35], [36], [37]で紹介されている第二価格秘密入札, オランダ型オークション, 第一価格入札方式というオークションの手法は耐戦略性の実現を目指し設計されている. 一方で, 英国型オークションでは, 入札者の効用の最大化を実現する一方で耐戦略性は満たさない. 英国型オークションでは, プレイヤーが入札価格を変更しなくなるまで入札価格の申告と公開を繰り返す. また, [35]では, あるオークションメカニズムが自分の評価値を正直に入札するという支配戦略を持つ時, そのメカニズムを誘引両立性(incentive compatible)または戦略的操作不可性(strategy-proofness)があると説明している. 戦略的操作不可性をもつメカニズムの設計は[38]でも扱われている. [38]では, エージェントが持ちうる効用関数の集合を考え, その上でナッシュ遂行できるようなメカニズムを考えるため, 社会選択環境で社会選択対応をナッシュ均衡で遂行するための必要条件, 十分条件を, マスキンの定理を使いて考察している. これらを活用し, 耐戦略性を満たした申告メカニズムを用いて効用関数の情報を得る必要がある.擬似勾配ゲーム
目標点を発見した後には, 目標点の安定化を行う. 目標点の安定化の際には, ゲームを動的システムとして表す必要がある. 非協力ゲームにおけるプレイヤーの振る舞い方をシステムとして表す手法のひとつとして,擬似勾配ゲーム[39][40][41]が存在する. 擬似勾配ゲームでは, 各プレイヤーの効用関数をプレイヤー自身の状態で偏微分したものを状態の微分とすることで, その状態での自分の効用をなるべく大きくする方向に状態を変化させるシステムを実現する. 疑似勾配ゲームには, 状態の偏微分に感度という定数をかけたものをシステムとする手法も存在する.税・補助金アプローチ
非協力ゲームにおいてプレイヤーの振る舞いを制御し, 目標点を安定化させる手法として,税・補助金アプローチ[1][42][43]が用いられている. 税・補助金アプローチでは, 税または補助金をインセンティブとし, 目標点が安定になるようプレイヤーの効用関数を変化させる手法である. 状態に対応した税または補助金を設定し, プレイヤーから税をとるもしくはプレイヤーに補助金を与える, すなわち効用関数から税を引く, もしくは効用関数に補助金を足すことで制御を行う. 例えば, [44]は, プレイヤーの元々の効用関数に対し, 定数を用いて状態に依存する値をプレイヤー1の効用関数には補助金として加え, プレイヤー2からは税として引くことにより, ナッシュ均衡が安定となるように効用関数を変更し, ナッシュ均衡の安定化を達成している. なお,この例では全プレイヤーでのインセンティブの合計が0となる設定がされている.適応制御
平衡点を安定化するためには, 税・補助金を設計する必要がある. しかし, 申告された効用関数の情報を用いる場合, 真の効用関数は未知となる. したがって, 未知のシステムを目標点に対して安定化する必要がある. 未知のシステムの安定化を行う手法は複数存在する. [45]では, recursive delayed frrdback controller(recursive DFC)を用いることで, 平衡点とシステムについて未知のまま, 極配置により平衡点の安定化を達成している. [32]ではモデルの推定にニューラルネットワーク(NN)を利用している. NNの重みベクトルを応答の履歴を用いて更新し, モデルの推定を行っている. 一方で, 未知のシステムの安定化に用いられる手法に適応制御が存在する. [46]では, 入力が量子化された非線形の未知のシステムを, 適応制御のゲインを設計することで安定化している. [47]では, 1次元の未知の線型離散システムの安定化を適応制御を用いて実現している.研究目的
問題設定
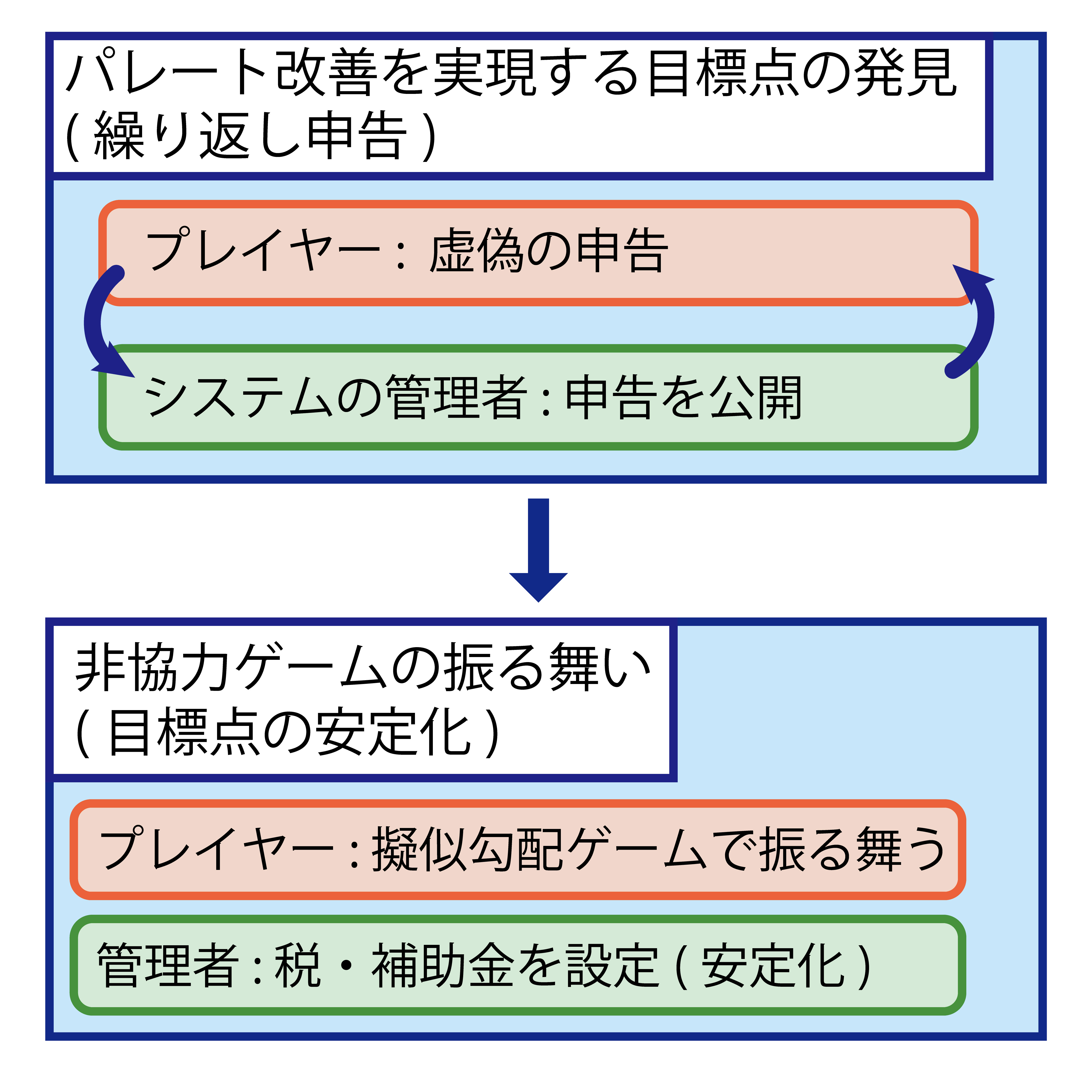 |
| 図1 : システムの全体像 |
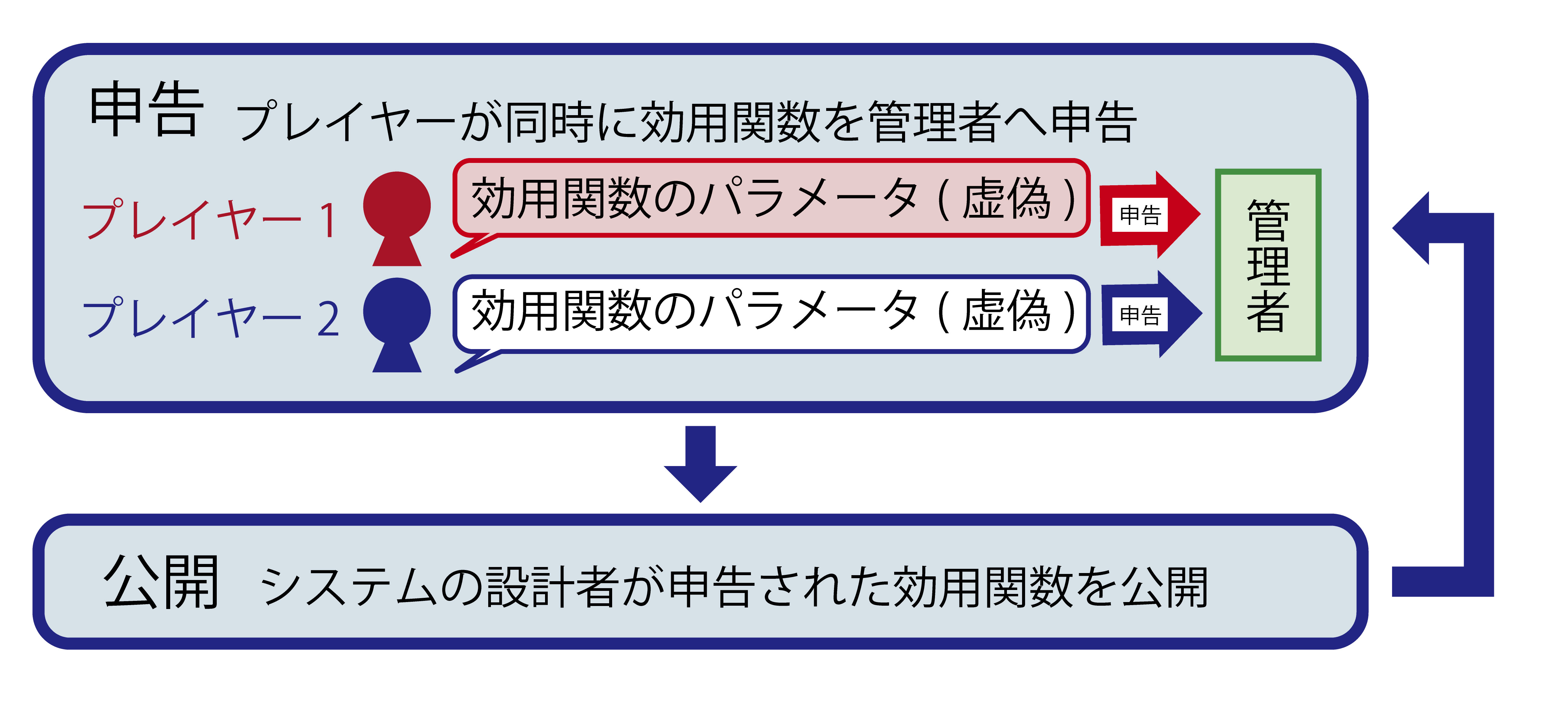 |
| 図2 : 繰り返し申告システム |
研究結果
実際に, 本来のナッシュ均衡xnashに対してパレート改善が実現する点x*を発見できた場合の非協力ゲームの振る舞いは図3のようになった. システムの管理者が何も行わない場合, 非協力ゲームは本来のナッシュ均衡xnashへと収束する. 一方で, システムの管理者が繰り返し申告によりx*の情報を得, 税・補助金による制御を行った場合には, ナッシュ均衡よりも効用が高くなる点x*へ収束していることが確認できる。
 |
| 図3 : 制御時・非制御時のプレイヤーの振る舞い |
参考文献
[1] K. Takafumi, and M. Takurou, and U. Toshimitsu, "A control method of dynamic selfish routing based on a state-dependent tax," IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, vol. 96, no. 8, pp. 1794--1802, 2013.
[2] 兵藤 哲朗, 高橋 洋二, 中里 亮, 駐車場情報提供システムを考慮した交通行動モデルの検討, 土木計画学研究・論文集, 1996, 13 巻, pp. 855-860, 2010.
[3] K. Ma, and C. Wang, and J. Yang, and C. Hua, and X. Guan, "Pricing Mechanism With Noncooperative Game and Revenue Sharing Contract in Electricity Market," IEEE Transactions on Cybernetics, vol. 49, no. 1, pp. 97-106, 2019.
[4] C. Liu, C. Li, K. Deng, L. Xu and X. Yu, "The optimal EV charging/discharging strategy in smart grid from a perspective of sharing-economy," IECON 2017 - 43rd Annual Conference of the IEEE Industrial Electronics Society, pp. 7497-7502, 2017.
[5] D. Xiang and E. Wei, "DYNAMIC PRICE DISCRIMINATION IN DEMAND RESPONSE MARKET: A BILEVEL GAME THEORETICAL MODEL," 2018 IEEE Global Conference on Signal and Information Processing, Anaheim, pp. 951-955, 2018.
[6] A. Goswami, and R. Gupta, and G. S. Parashari, "Reputation-Based Resource Allocation in P2P Systems: A Game Theoretic Perspective," IEEE Communications Letters, vol. 21, no. 6, pp. 1273-1276, 2017.
[7] E. Altman, F. De Pellegrini, R. El-Azouzi, D. Miorandi, and T. Jimenez, "Emergence of equilibria from individual strategies in online content diffusion," 2013 Proceedings IEEE INFOCOM, pp. 3255-3260, 2013.
[8] H. V. Zhao, W. S. Lin and K. J. R. Liu, "Game-theoretic analysis of maximum-payoff multiuser collusion," 2008 15th IEEE International Conference on Image Processing, pp. 1276-1279, 2008.
[9] Wang Haobo, Ma Junhai and Peng Jing, "Complex dynamics in a repeated game model with lagged structure," 2010 2nd International Asia Conference on Informatics in Control, Automation and Robotics, pp. 122-125, 2010.
[10] 阿部 雅明, 『環境の経済的評価 : CVMによる風力発電施設評価を研究事例として』, 新潟産業大学経済学部紀要, no. 33, pp. 39-55, 2007.
[11] P. Schöttle, A. Laszka, B. Johnson, J. Grossklags, and R. Böhme, "A game-theoretic analysis of content-adaptive steganography with independent embedding," 21st European Signal Processing Conference, pp. 1-5, 2013.
[12] K. C. Nguyen, T. Alpcan, and T. Başar, "Security games with decision and observation errors," Proceedings of the 2010 American Control Conference, pp.510-515, 2010.
[13] X. Gao, W. Zhong, and Shue Mei, "Equilibrium stability of a nonlinear heterogeneous duopoly game with extrapolative foresight," Mathematics and Computers in Simulation, vol. 82, num. 11, pp. 2069-2078, 2012.
[14] B. Chakravorti, and J. P. Conley, and B. Taub, "Probabilistic cheap talk," Social Choice and Welfare, vol. 19, no. 2, pp. 281-294, 2002.
[15] W. M. Haddad, V. Chellaboina, and T. Hayakawa, "Robust adaptive control for nonlinear uncertain systems," Proceedings of the 40th IEEE Conference on Decision and Control, vol. 2, pp. 1615-1620, 2001.
[16] H. Mukaidani, "Nash games for multiparameter singularly perturbed systems with uncertain small singular perturbation parameters," in IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 52, no. 9, pp. 586-590, 2005.
[17] H. Yang, X. Xie, and A. V. Vasilakos, "Noncooperative and Cooperative Optimization of Electric Vehicle Charging Under Demand Uncertainty: A Robust Stackelberg Game," IEEE Transactions on Vehicular Technology, vol. 65, no. 3, pp. 1043-1058, 2016.
[18] M. Jimenez-Lizarraga and L. Fridman, "Robust Nash Strategies based on Integral Sliding Mode Control for a Two Players Uncertain LQ Game," Informatio and Control, pp. 354-354, 2007.
[19] F. Amato, M. Mattei, and A. Pironti, "Robust strategies for Nash linear quadratic games under uncertain dynamics," Proceedings of the 37th IEEE Conference on Decision and Control, vol. 2, pp. 1869-1870, 1998.
[20] Z. Zahedi, M. M. Arefi, and A. Khayatian, "Convergence without oscillation to Nash equilibria in non-cooperative games with quadratic payoffs," 2017 Iranian Conference on Electrical Engineering (ICEE), pp. 651-655, 2017.
[21] P. Frihauf, M. Krstic, and T. Başar "Nash equilibrium seeking with infinitely-many players," Proceedings of the 2011 American Control Conference, pp. 3059-3064, 2011.
[22] M. Ye, "A RISE-based Distributed Robust Nash Equilibrium Seeking Strategy for Networked Games," 2019 IEEE 58th Conference on Decision and Control, pp. 4047-4052, 2019.
[23] W. A. van den Broek, J. C. Engwerda, and J. M. Schumacher, "Robust Equilibria in Indefinite Linear-Quadratic Differential Games," Journal of Optimization Theory and Applications, vol. 119, no. 3, pp. 565-595, 2003.
[24] Xiao-Feng Wang, Wei-Yi Liu, Jin Li, and Yun Zhao, "Using Bayesian networks to model the belief in the opponent in static game with incomplete information," Proceedings of 2004 International Conference on Machine Learning and Cybernetics, vol. 1, pp. 249-252, 2003.
[25] P. V. Reddy and G. Zaccour, "Feedback Nash Equilibria in Linear-Quadratic Difference Games With Constraints," IEEE Transactions on Automatic Control, vol. 62, no. 2, pp. 590-604, 2017.
[26] M. Basin, and M. Jiménez-Lizárraga, "Equilibrium in Linear Quadratic Stochastic Games with Unknown Parameters," 2008 3rd International Conference on Innovative Computing Information and Control, pp. 215-215, 2008.
[27] Jian-xi Lin and Yong-jun Zhang, "Study on hydropower pricing model based on pareto improvement criterion," 2011 IEEE Power Engineering and Automation Conference, pp. 377-379, 2011.
[28] 坂井 勝哉, and 日下部 貴彦, and 朝倉 康夫, "ボトルネック通行権取引制度が利用者の効用に及ぼす影響とパレート改善―スケジュール制約と料金抵抗の異質性に着目して―," 土木学会論文集D3(土木計画学), vol. 72, no.5 pp. 607-616, 2016.
[29] J. Yang, and S. Yang, and P. Ni, " Vector Tabu Search Algorithm With Enhanced Searching Ability for Pareto Solutions and Its Application to Multiobjective Optimizations," IEEE Transactions on Magnetics, vol. 52, no. 3, pp. 1-4, 2016.
[30] B. Salvador, "An introduction to strategy-proof social choice functions," Soc Choice Welfare, no. 18, pp. 619–653, 2001.
[31] P. Yang, G. Tang and A. Nehorai, "Optimal time-of-use electricity pricing using game theory," 2012 IEEE International Conference on Acoustics, Speech and Signal Processing 2012, pp. 3081-3084, 2012.
[32] D. Zhao, Q. Zhang, D. Wang, and Y. Zhu, "Experience Replay for Optimal Control of Nonzero-Sum Game Systems With Unknown Dynamics," in IEEE Transactions on Cybernetics, vol. 46, no. 3, pp. 854-865, 2016.
[33] Y. Wu, B. Wang, K. J. R. Liu, and T. C. Clancy, "Repeated open spectrum sharing game with cheat-proof strategies," IEEE Transactions on Wireless Communications, vol. 8, num. 4, pp. 1922-1933, 2009.
[34] B. Awerbuch, and Y. Azar, and A. Meyerson, "Reducing Truth-Telling Online Mechanisms to Online Optimization," Proceedings of the Thirty-Fifth Annual ACM Symposium on Theory of Computing, pp. 503–510, 2003.
[35] 横尾 真, 岩崎 敦, 櫻井 祐子, 岡本 吉央, "『計算機科学者のためのゲーム理論入門』シリーズ第3回 メカニズムデザイン(基礎編)," コンピュータ ソフトウェア, vol. 29, no. 4, pp. 4_15-4_31, 2012
[36] 横尾 真, 岩崎 敦, 櫻井 祐子, 岡本 吉央, 『計算機科学者のためのゲーム理論入門』シリーズ第4回 メカニズムデザイン(応用編), コンピュータ ソフトウェア, 30 巻, 1 号, pp. 1_34-1_52, 2013.
[37] 丸茂 新, "Vickrey教授の"新たな料金制度"について," 商学論究, no. 37, 1962.
[38] 西條 辰義, 大和 毅彦, "自然なメカニズムデザインをめざして," http://www.me.titech.ac.jp/~yamato/pdf/2005-11-sy.pdf, 2005
[39] J. S. Shamma, and G. Arslan, "Dynamic fictitious play, dynamic gradient play, and distributed convergence to Nash equilibria," IEEE Transactions on Automatic Control, vol. 50, no. 3, pp. 312-327, 2005.
[40] M. Dindo{\v{s}}, and C. Mezzetti, "Better-reply dynamics and global convergence to Nash equilibrium in aggregative games," Games and Economic Behavior, vol. 54, no. 2, pp. 261-292, 2006.
[41] J. B. Rosen, "Existence and Uniqueness of Equilibrium Points for Concave N-Person Games," Wiley, Econometric Society, vol. 33, no. 3, pp. 520-534, 1965.
[42] T. Alpcan, and L. Pavel, and N. Stefanovic, "A control theoretic approach to noncooperative game design," Proceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference, pp. 8575-8580, 2009.
[43] T. Kanazawa, and T. Misaka, and T. Ushio, and Y. Fukumoto, "A control method of selfish routing based on replicator dynamics with capitation tax and subsidy," 2009 IEEE Control Applications, (CCA) Intelligent Control, (ISIC), pp. 249-254, 2009.
[44] Y. Yan, and T. Hayakawa, "Stability and stabilization of nash equilibrium for noncooperative dynamical systems with tax/subsidy approach," Preprint submitted to Automatica, 2019.
[45] J. Zhu, and Y. Tian, "Pole placement and stabilization of discrete systems with unknown equilibrium points," 2006 Chinese Control Conference, pp. 867-872, 2006.
[46] T. Hayakawa, and H. Ishii, and K. Tsumura, "Adaptive quantized control for linear uncertain discrete-time systems," Proceedings of the 2005, American Control Conference, 2005., vol. 7, pp. 4784-4789, 2005.
[47] T. Hayakawa, "Adaptive symbolic feedback for one-dimensional discrete-time uncertain systems," 2013 European Control Conference (ECC), pp. 388-391, 2013.